DSP-SLAM: Object Oriented SLAM with Deep Shape Priors 3DV 2021
- Jingwen Wang UCL
- Martin Rünz UCL
- Lourdes Agapito UCL
Abstract
We propose DSP-SLAM, an object-oriented SLAM system that builds a rich and accurate joint map of dense 3D models for foreground objects, and sparse landmark points to represent the background. DSP-SLAM takes as input the 3D point cloud reconstructed by a feature-based SLAM system and equips it with the ability to enhance its sparse map with dense reconstructions of detected objects. Objects are detected via semantic instance segmentation, and their shape and pose is estimated using category-specific deep shape embeddings as priors, via a novel second order optimization. Our object-aware bundle adjustment builds a pose-graph to jointly optimize camera poses, object locations and feature points. DSP-SLAM can operate at 10 frames per second on 3 different input modalities: monocular, stereo, or stereo+LiDAR. We demonstrate DSP-SLAM operating at almost frame rate on monocular-RGB sequences from the Freiburg and Redwood-OS datasets, and on stereo+LiDAR sequences on the KITTI odometry dataset showing that it achieves high-quality full object reconstructions, even from partial observations, while maintaining a consistent global map. Our evaluation shows improvements in object pose and shape reconstruction with respect to recent deep prior-based reconstruction methods and reductions in camera tracking drift on the KITTI dataset.
Overall Video
Method
DSP-SLAM takes a live stream of monocular or stereo images, infers object masks, and outputs a joint map of point features and dense objects. The sparse SLAM backbone provides per-frame camera poses and a 3D point cloud. At each keyframe, 7-DoF object pose and a shape code is estimated for each new detected object instance, using a combination of 3D surface consistency and rendered depth losses on the 3D points. Reconstructed objects are added to the joint factor graph where object poses, 3D feature points and camera poses are optimized jointly via Bundle Adjustment.
Reconstruction from Single View + Sparse LiDAR
In this section we show some results of our reconstruction pipeline. First, we present a demo of how our reconstruction pipeline could recover accurate object psoe and shape from noisy initial pose estimate and zero shape code using a combination of 3D surface consistency and rendered depth and silhouette. Note that the our approach uses Gauss-Newton solver with analytical Jacobians and could converge very fast for a single object (in the order of ~100 ms). The demo is slown down for better visualization.
We also show some reconstruction results from selected frames in KITTI dataset. Note the level of details of the reconstruction and how they fit well to the LiDAR points. It is worth highlighting that our method only takes very few LiDAR points (as few as 50) per object, while in the demo above and the results below all the LiDAR mearesuements are shown for better visualization.



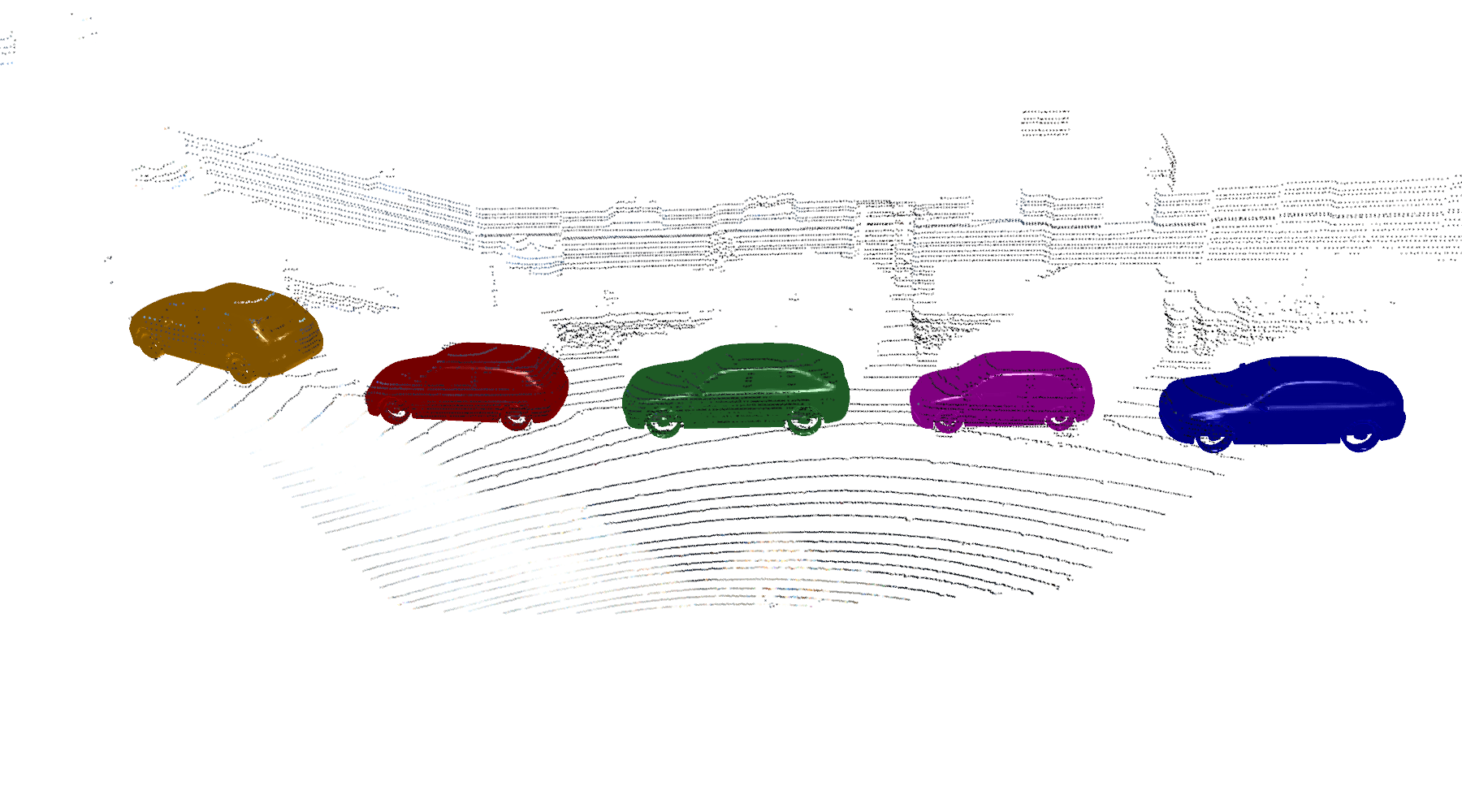







KITTI Dataset
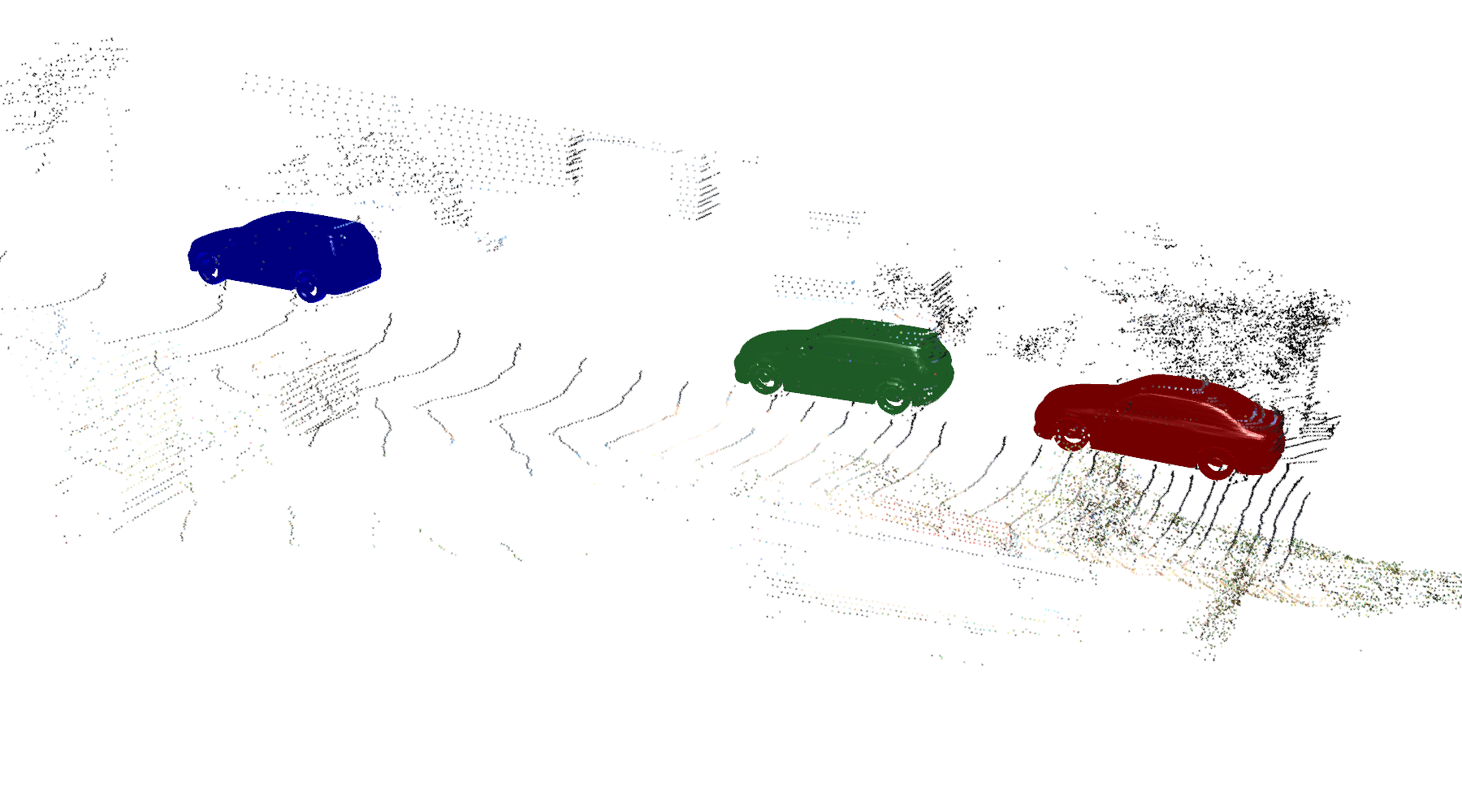
From now on we will present results of our full SLAM system. We first show some example live demos of DSP-SLAM running on KITTI sequences with stereo+LiDAR input. Initial object poses are estimated using off-the-shelf LiDAR-based 3D detector, and the number of LiDAR points required for object reconstruction was set to 100 per object. Note the level of details of the object reconstruction, the number of objects being reconstructed, and how the duplicated objects, caused by accumulated drift, are merged via loop closure. These results show DSP-SLAM's capability of building consistent map of objects with high level of detail at very large scale (over 400 objects).
KITTI-00
KITTI-07
Freiburg Cars Dataset
As our optimization loss for object reconstruction only requires very few number of 3D points, next we show those points can also come from monocular SLAM points.
First, we show results on Freiburg Cars dataset, in which camera is moving around a single car. As the scene is sharply different from KITTI, we changed our system's settings
as follows:
Initial object pose is obtained via running PCA on the SLAM points belonging to the object. We run shape and pose optimization every 5 keyframes, with each optimization
continuing from the previous one.
Car-001
Car-010
Redwood-OS Chairs Dataset
In order to demonstrate our method's performance on other shape categories, we also run our system on Redwood-OS chairs dataset with monocular input. Accuracy is slightly worse than on cars as chairs have much more complex shape variations. Results are promising nonetheless – our method still produces dense meshes that capture the overall object shape from monocular RGB-only sequences, in quasi-real time (> 15Hz).
Chair-09374
Chair-01053
Chair-02484
Chair-09647
Related links
Code and data are available at here. Our pre-trained shape embedding is based on DeepSDF (Park et al. (2019)). The full SLAM system was implemented based on ORB-SLAM2.
Our differentiable renderer was inspired by NodeSLAM (Sucar et al. (2020)), detailed derivation of the analytical graidents follows Tulsiani et al. (2017).
Related work that's also exploiting shape priors for object reconstruction:
Citation
If you found this work is useful in your own research, please consider citing our paper:
@inproceedings{wang2021dspslam,
title={DSP-SLAM: Object Oriented SLAM with Deep Shape Priors},
author={Wang, Jingwen and R{\"u}nz, Martin and Agapito, Lourdes},
booktitle={2021 International Conference on 3D Vision (3DV)},
pages={1362--1371}
year={2021}
organization={IEEE}
}Acknowledgements
Jingwen Wang is funded by CDT in Foundational AI at UCL. The website template was borrowed from Mip-NeRF.
Please send any questions or comments to Jingwen Wang.